Today, Facebook announced that it’s expanding photo and video fact-checking capabilities to all of its third-party fact-checking partners. Product Manager Tessa Lyons sat down with us to explain how the company is using technology, along with human reviewers, to find and take action on misinformation in these new visual formats — and where the company needs to keep investing.
Facebook has been tackling article-based misinformation for a while now, but photos and videos are a relatively new frontier. What’s the difference between those two types of misinformation?
We started our work on misinformation with articles because that’s what people in the US were telling us was the most prevalent form of false news they were seeing, and also because that was the way that financially motivated bad actors were making money off of misinformation. What they’d do is they’d share articles that contain misinformation — and people would be surprised by the headlines because they were false. So they’d click on those articles and land on websites where those bad actors were monetizing their impressions with ads.
So it was spammy, “gotcha” content.
Right, they were financially motivated spammers. So we focused on articles to go after and disrupt those financial incentives and to respond to what we were hearing from people. But we know from our research in countries around the world — and in the US — that misinformation isn’t limited to articles. Misinformation can show up in articles, in photos, in videos. The same false claim can appear as an article headline, as text over a photo or as audio in the background of a video. In order to fight misinformation, we have to be able to fact-check it across all of these different content types.
You mentioned people in the US said they saw more misinformation in articles, rather than in other formats. Is that true around the world?
The degree to which there’s misinformation in articles, photos or videos varies country to country — in part because the amount of photos or videos versus articles in people’s News Feed varies country by country. In some countries, articles make up a greater proportion of people’s News Feed than in others. Visual content might also lean more toward photos than videos in some countries, or vice versa.
Why is that?
Well first and foremost, News Feed is personalized. So what you see in your News Feed is personal to you and you might see more articles, photos or videos based on the people you’re friends with, the Pages you follow, and the way you interact with the stories in your News Feed. But we know there are some things that make the News Feed experience more similar for people in some countries. So for example, in countries where many people are worried about their bandwidth, people might be less inclined to click on videos. So people in those countries might see fewer videos in their News Feed overall — which means less video-based misinformation.
There are other differences in the media landscape and literacy rates that impact how photo and video misinformation is interpreted too. In countries where the media ecosystem is less developed or literacy rates are lower, people might be more likely to see a false headline on a photo, or see a manipulated photo, and interpret it as news, whereas in countries with robust news ecosystems, the concept of “news” is more tied to articles.
Can you use the same technology to catch all those different types of misinformation?
Yes and no. When we fight misinformation, we use a combination of technology and human review by third-party fact-checkers. When it comes to articles, we use technology to, first, predict articles that are likely to contain misinformation and prioritize those for fact-checkers to review. Second, once we have a rating from a fact-checker, we use technology to find duplicates of that content. We’ve been doing this with links for a while; for example, a fact-checker in France debunked the claim that you can save a person having a stroke by using a needle to prick their finger and draw blood. This allowed us to identify over 20 domains and over 1,400 links spreading that same claim. Now, we’ll apply a similar technology to identify duplicates of photos and videos that have been debunked by fact-checkers so that we can make the most of each rating from fact-checking partners.
While there are similarities in the technology, there are also important differences in how we identify articles versus photos and videos.
Okay — let’s talk about that first stage: using technology to predict what’s likely to be false.
When we’re predicting articles that are likely to contain misinformation, we use signals like feedback from our community, telling us that a link they’re seeing is false news. We look at whether the comments on the post include phrases that indicate readers don’t believe the content is true. We also look at things like whether the Pages that shared the content have a history of sharing things that have been rated false by fact-checkers. Signals like these apply to articles, photos and videos.
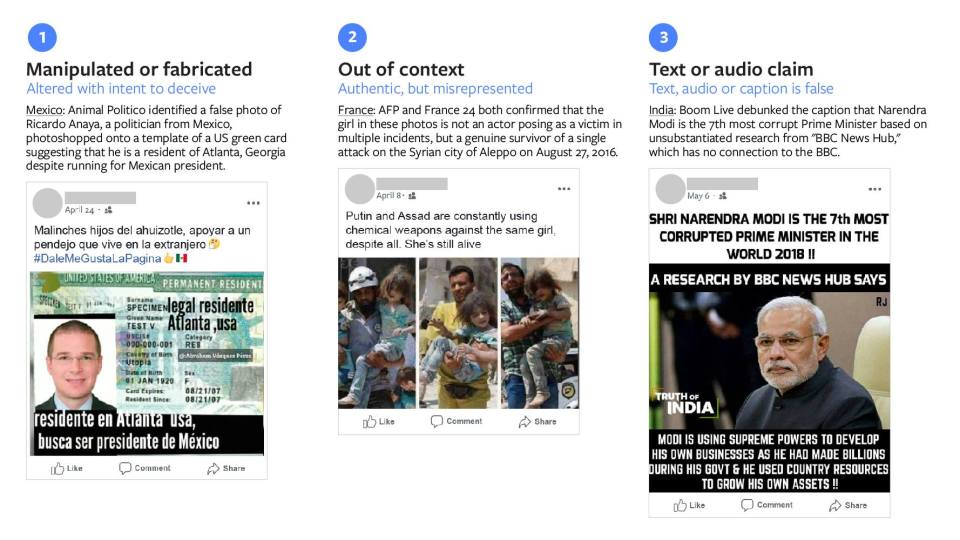
So a lot of the work we’ve done to predict potentially false links also helps us with photos and videos. However, there are also some differences. When we talk about misinformation in photos and videos, we break it into three categories: manipulated, taken out of context, or includes a false text or audio claim. So let’s take each of those. Manipulated: You can have a photo that’s been manipulated to suggest that a person was in the picture when they weren’t. Or if someone is taking an action in a photo — like holding something — you could manipulate it to make it look like they’re holding something else.
So like, when you see a photo of a shark swimming on the highway.
Right, that’s a great example of a manipulated photo. For manipulated videos, the term “deepfakes” is something a lot of people in the misinformation space have been talking about — where, for example, you can make it look like a public figure was saying things that they never actually said, but in the video their mouth would actually be moving, and it would sound like their voice. So the shark example would be what we classify as a manipulated piece of media.
The second category is things taken out of context. So, a photo of a conflict zone that’s being shared in a way that suggests it’s happening in a different time or place. Same with video.
The third category is false audio or text claims. Just as you can have false headlines or text in an article, that claim could be overlaid on a photo or spoken by someone in a video. The same way that someone could make a false claim in an article, they could also make a false claim in the caption on a photo or while speaking in a video.
So those are the three categories that we think about. And there are different ways we can use technology to predict each of them, and our ability to do so is at different levels of development.
So how far along is the technology to predict misinformation in each of those three categories?
We’ve started making progress in identifying things that have been manipulated. But figuring out whether a manipulated photo or video is actually a piece of misinformation is more complicated; just because something is manipulated doesn’t mean it’s bad. After all, we offer filters on Facebook Stories and in some ways that’s a manipulation, but that’s obviously not the kind of stuff we’re going after with our fact-checking work. But we are now able to identify different types of manipulations in photos, which can be a helpful signal that maybe something is worth having fact-checkers take a look at.
Understanding if something has been taken out of context is an area we’re investing in but have a lot of work left to do, because you need to understand the original context of the media, the context in which it’s being presented, and whether there’s a discrepancy between the two. To examine a photo of a war zone, figure out its origin, and then assess whether that context is accurately represented by the caption now circulating with that photo, we still need a degree of human review. And that’s why we rely on fact-checkers to leverage their journalistic expertise and situational understanding.
For photos or videos that make false text or audio claims, we can extract the text using optical character recognition (OCR) or audio transcription, and see if that text includes a claim made that matches something fact-checkers have debunked. If it does, we’ll surface it to fact-checkers so they can verify the claim is a match. At the moment, we’re more advanced with using OCR on photos than we are with using audio transcription on videos.
So what about the other side, finding duplicates of false claims?
Well, the way you find duplicates of articles is through natural language processing, which is a machine learning technique that can be used to find duplicates of text with slight variations. For photos, we’re pretty good at finding exact duplicates, but often times we’ll see that someone will add small changes to the photo which adds a layer of complexity; the more a photo shifts from its original form, the harder it is for us to detect and enforce against. So we need to continue to invest in technology that will help us identify very near duplicates that have been changed in small ways.